El Desafío de la Eficiencia en Modelos de Lenguaje
Los Modelos de Lenguaje y su Papel en la Inteligencia Artificial
Los grandes modelos de lenguaje o LLMs son una piedra angular en el campo de la Inteligencia Artificial (IA). Estos modelos, como GPT-3 o BERT, han revolucionado cómo las máquinas comprenden y generan lenguaje humano. Se utilizan en una variedad de aplicaciones, desde asistentes virtuales hasta herramientas de traducción automática.
Sin embargo, existen desafíos significativos por resolver, especialmente en términos de eficiencia. A medida que estos modelos crecen en tamaño y complejidad, también lo hace su consumo de recursos. Esto incluye un uso intensivo de memoria y una menor velocidad de procesamiento, lo que puede limitar su aplicación en dispositivos con recursos limitados y aumentar los costos operativos.
La Necesidad de Modelos Más Eficientes
El desafío principal es cómo hacer que estos modelos de lenguaje sean más eficientes sin sacrificar su capacidad para comprender y generar lenguaje de manera efectiva. La eficiencia no solo implica rapidez en el procesamiento del lenguaje, sino también la capacidad de recordar y utilizar adecuadamente la información anterior, una habilidad crucial para el aprendizaje en contexto.
En respuesta a la necesidad de modelos de lenguaje más eficientes, el equipo de Together.ai ha presentado un estudio cuyo objetivo es mejorar la eficiencia en la velocidad y consumo de memoria de los modelos de lenguaje sin comprometer su capacidad de recordar y aprender en contexto.
En este post, exploraremos este estudio y cómo Based está marcando una diferencia significativa en eficiencia y capacidad de recuerdo, superando desafíos enfrentados por modelos previos como Mamba y Transformers tradicionales.
¿Qué es Based?
La Innovación de BASED
Lo que hace a Based único es su combinación de dos técnicas de atención ya conocidas: la atención de ventana deslizante y la atención lineal. Al fusionar estas dos técnicas, Based logra un delicado equilibrio entre dos objetivos aparentemente opuestos: mantener una fuerte capacidad de recordar información y al mismo tiempo ser extremadamente eficiente en términos de procesamiento y uso de memoria.
Atención de Ventana Deslizante
La atención de ventana deslizante en Based ayuda a limitar el tamaño del estado recurrente, lo que es esencial para reducir la carga de memoria del modelo. Esto permite al modelo concentrarse en partes más pequeñas de un texto a la vez, mejorando así la eficiencia sin perder la capacidad de comprender el contexto.
Atención Lineal
Por otro lado, la atención lineal elimina la necesidad de operaciones softmax complejas, simplificando y acelerando el proceso de atención. Esto es crucial para el modelado de interacciones de largo alcance entre tokens en el texto.
El Impacto de BASED
Con esta innovadora combinación, Based no solo mejora la eficiencia de procesamiento, sino que también mantiene una calidad competitiva en tareas de modelado de lenguaje, abriendo así nuevas posibilidades para aplicaciones en tiempo real y en dispositivos con limitaciones de recursos.
Innovaciones Clave en BASED
La arquitectura Based no sólo supone una mejora incremental en el campo de los modelos de lenguaje; como hemos visto, representa una innovadora fusión de dos técnicas de atención bien establecidas. Vamos a desglosar cómo cada una de estas técnicas contribuye a la eficacia general de Based.
1. Atención de Ventana Deslizante: Enfocándose en lo Que Importa
- Concepto: La atención de ventana deslizante limita la cantidad de texto que el modelo examina en un momento dado. Piensa en ello como leer un libro mirando solo una página a la vez, en lugar de tratar de absorber todo el libro de una sola vez.
- Beneficio para Based: Esta técnica reduce significativamente la cantidad de memoria requerida, ya que el modelo no necesita recordar cada parte del texto todo el tiempo. Además, permite al modelo enfocarse en segmentos relevantes de texto, mejorando la precisión en la generación y comprensión del lenguaje.
2. Atención Lineal: Simplificación y Velocidad
- Concepto: La atención lineal simplifica el mecanismo de atención al eliminar la necesidad de la operación softmax, común en muchos modelos de lenguaje. Esto reduce la complejidad computacional.
- Beneficio para Based: Esta simplificación se traduce en una mayor velocidad de procesamiento, lo que es vital para aplicaciones en tiempo real. Además, permite al modelo gestionar efectivamente las interacciones a largo plazo entre palabras o frases en un texto.
Balanceando Recuerdo y Eficiencia
- Combinación Estratégica: Based equilibra hábilmente estas dos técnicas. Mientras que la atención de ventana deslizante se enfoca en interacciones locales, la atención lineal maneja las globales, asegurando que el modelo no pierda de vista el «panorama general» del texto.
- Impacto en el Aprendizaje en Contexto: Esta combinación permite a Based recordar eficientemente información relevante y aplicarla en contextos nuevos, una habilidad esencial para el aprendizaje en contexto.

Beneficios y Resultados de BASED
Based no es solo una promesa teórica, sino que ha demostrado su valía a través de resultados impresionantes en varias pruebas y aplicaciones
1. Eficiencia en el Procesamiento y Uso de la Memoria
- Rendimiento Superior: Comparado con modelos anteriores como FlashAttention-2 y Mamba, Based ha demostrado ser significativamente más rápido y eficiente en el uso de memoria.
- Aplicaciones Prácticas: Esta eficiencia abre nuevas puertas para la implementación de modelos de lenguaje avanzados en dispositivos con recursos limitados, como teléfonos inteligentes y tablets.
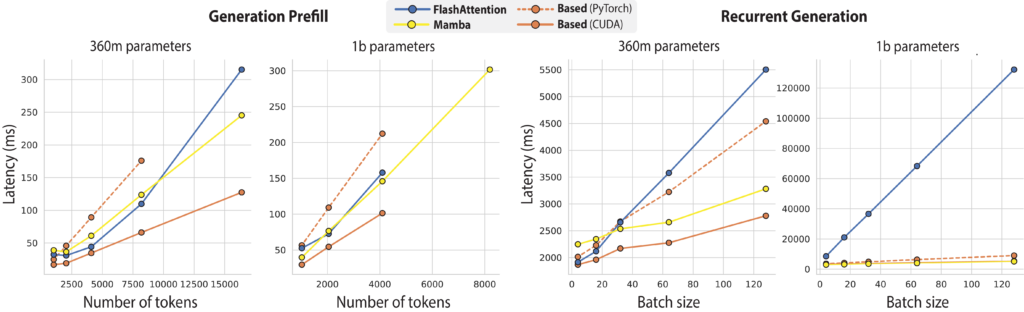
2. Excelencia en Tareas de Recordación y Aprendizaje en Contexto
- Dominando Tareas Complejas: En tareas que requieren una fuerte capacidad de recordación, como la extracción de información de documentos extensos y la comprensión de lectura, Based ha superado a otras arquitecturas subcuadráticas.
- Aprendizaje en Contexto: Su capacidad para realizar aprendizaje en contexto, como se demostró en pruebas de comprensión de lenguaje natural con pocos ejemplos (few-shot), destaca la habilidad de Based para adaptarse y aprender de situaciones nuevas.
3. Resultados Concretos: Un Vistazo a las Pruebas
- Desempeño en Benchmarks: En benchmarks estándar de modelado de lenguaje y en tareas específicas que exigen un alto nivel de recordación, Based ha mostrado resultados prometedores, aunque aún hay espacio para mejoras en comparación con los modelos de Transformer más potentes.
- Implicaciones: Estos resultados no solo validan la eficacia de Based, sino que también sugieren direcciones futuras para la optimización y desarrollo de modelos de lenguaje aún más avanzados.
Limitaciones y Futuro de BASED
A pesar de los avances significativos que representa Based, es importante reconocer que no es una solución definitiva y presenta ciertas limitaciones
1. Comparación con Modelos Transformer Tradicionales
- Desempeño en Algunas Tareas: Aunque Based sobresale en eficiencia y tareas específicas de recordación, todavía no alcanza el nivel de desempeño de los modelos Transformer más avanzados en algunas aplicaciones complejas.
- El Equilibrio entre Eficiencia y Capacidad: Esta diferencia destaca la continua necesidad de equilibrar eficiencia y capacidad de procesamiento en los modelos de lenguaje.
- Es importante señalar que el estudio afirma que Based no es la única arquitectura que pueda funcionar en este punto de la curva de compromiso. Por ejemplo, podemos sustituir la atención de la ventana deslizante por evoluciones cortas (tamaño de filtro 3) y lograr un rendimiento similar en 0,1 puntos de perplejidad.
2. Desafíos en Aplicaciones de Largo Alcance
- Recordación en Contextos Extensos: Aunque Based maneja bien la recordación en ciertos contextos, puede haber limitaciones cuando se trata de secuencias extremadamente largas o contextos muy complejos.
Mirando hacia el Futuro
- Innovaciones Continuas: La arquitectura Based abre el camino para futuras innovaciones. Los resultados obtenidos hasta ahora son un sólido punto de partida para desarrollar modelos aún más avanzados y eficientes.
- Potencial sin Explorar: Existe un amplio margen para explorar y expandir las capacidades de Based, especialmente en su aplicación a diferentes tipos de tareas de procesamiento de lenguaje.
Conclusión y Perspectivas
Based representa un avance significativo en el campo de los modelos de lenguaje, ofreciendo un equilibrio notable entre eficiencia y capacidad de recordación. Esta arquitectura destaca no solo por su rendimiento en tareas específicas, sino también por su potencial para hacer que la tecnología de IA sea más accesible y aplicable en una variedad de contextos
Impacto a Largo Plazo
- Inspirando Futuras Innovaciones: Based no solo mejora el estado actual de la tecnología de modelos de lenguaje, sino que también inspira nuevas direcciones en la investigación y desarrollo de IA.
- Aplicaciones Prácticas y Accesibilidad: La eficiencia y capacidad de Based lo hacen ideal para aplicaciones en dispositivos con limitaciones de recursos, abriendo así nuevas oportunidades en el uso de IA en la vida cotidiana.
Mas información en:
Enlaces Relacionados: