Introducción
En la vanguardia de la innovación en inteligencia artificial (IA), nos encontramos con desarrollos que están remodelando no solo cómo interactuamos con la tecnología, sino también cómo esta puede especializarse en campos tan críticos como la medicina. Un ejemplo destacado de este avance es Medprompt, una metodología desarrollada por un equipo de investigadores de Microsoft, que abre un nuevo horizonte en la aplicación de modelos generales de IA, como GPT-4, en el ámbito médico. Este post profundiza en el estudio titulado «Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine«, liderado por H. Nori y colaboradores, para explorar cómo Medprompt logra dirigir modelos generalistas hacia un rendimiento especializado, rivalizando e incluso superando a modelos específicamente afinados para tareas médicas.
El estudio de Medprompt no solo destaca por su aplicación en la medicina, sino también por su enfoque innovador y las implicaciones que tiene para el futuro de la inteligencia artificial en aplicaciones especializadas. Al comprender y analizar Medprompt, no solo apreciamos una mejora en la eficiencia y precisión de los modelos de IA, sino que también abrimos la puerta a nuevas posibilidades en el tratamiento de datos y resolución de problemas complejos en diversas áreas del conocimiento.
¿Qué es Medprompt?
Medprompt representa un avance significativo en el campo de la inteligencia artificial, particularmente en la forma en que se pueden utilizar los modelos generales fundacionales, como GPT-4, para tareas especializadas. Este método se basa en la composición de tres estrategias de prompting distintas, cada una aportando un elemento esencial para mejorar la capacidad del modelo de procesar y responder a problemas específicos en el campo médico.

- Dynamic Few Shots: Esta estrategia se centra en el aprendizaje basado en pocos ejemplos. En lugar de utilizar ejemplos fijos para cada tarea, Medprompt emplea un enfoque dinámico donde se seleccionan ejemplos de aprendizaje específicos para cada entrada de tarea, basándose en su similitud semántica. Esto se logra mediante un algoritmo de clustering k-NN en el espacio de incrustación, utilizando el modelo de incrustación de texto de OpenAI. De esta manera, los ejemplos de aprendizaje son siempre relevantes y representativos del caso específico que se está abordando.
- Self-Generated Chain of Thought (CoT): La Cadena de Pensamiento Autogenerada es otra piedra angular de Medprompt. En lugar de depender de expertos para generar ejemplos de razonamiento paso a paso, este método automatiza la creación de tales ejemplos. Utilizando GPT-4, se generan secuencias de razonamiento intermedias para cada ejemplo de entrenamiento, lo que mejora significativamente la capacidad del modelo para abordar problemas complejos. Este enfoque reduce el riesgo de generar cadenas de razonamiento incorrectas o alucinaciones.
- Majority Vote Ensembling: La tercera estrategia implica la combinación de múltiples salidas del modelo para mejorar la precisión predictiva. En el contexto de preguntas de opción múltiple, se emplea un truco adicional llamado «choice-shuffling», que aumenta la diversidad de las respuestas y, por lo tanto, la robustez de la respuesta final seleccionada.
La combinación de estas tres técnicas en Medprompt no solo ha demostrado ser efectiva en el ámbito médico, sino que también ha sentado un precedente en cómo los modelos generales pueden ser dirigidos para lograr un rendimiento de nivel especialista. Este enfoque representa un cambio significativo en la forma en que los modelos de IA pueden ser aplicados, pasando de la especialización mediante ajuste fino a la especialización mediante estrategias de prompting inteligentemente diseñadas.
Rendimiento de GPT-4 en Medicina mediante Medprompt
El estudio de Microsoft revela cómo, al aplicar Medprompt, GPT-4 muestra una notable habilidad para adaptarse a tareas médicas complejas. La clave de este éxito radica en la capacidad del modelo para interpretar y procesar información médica de manera más eficiente y precisa, gracias a la combinación de few-shots dinámicos, cadena de pensamiento autogenerada y ensembling de votación mayoritaria.
Esta metodología no solo eleva el nivel de precisión en respuestas específicas, sino que también mejora la capacidad del modelo para manejar preguntas de razonamiento complejo, una habilidad crucial en el campo de la medicina. Al utilizar ejemplos dinámicos y relevantes, junto con cadenas de razonamiento coherentes y bien fundamentadas, Medprompt permite a GPT-4 abordar preguntas médicas con un nivel de comprensión y precisión previamente inalcanzable para modelos generales.
Innovaciones con Medprompt+: Extensión y Mejoras
El concepto de Medprompt no se detiene en su aplicación inicial en medicina. Los investigadores han extendido esta metodología, creando Medprompt+, para abordar un rango aún más amplio de desafíos, particularmente en el benchmark MMLU (Measuring Massive Multitask Language Understanding). MMLU es una prueba de conocimiento general y habilidades de razonamiento de modelos de lenguaje a gran escala, cubriendo una amplia gama de áreas desde matemáticas básicas hasta historia, derecho, informática, ingeniería y medicina.
Medprompt+ toma la base de Medprompt y la amplía, aumentando el número de llamadas en ensemble de cinco a veinte y adaptando las estrategias de prompting para abordar una diversidad aún mayor de preguntas. Esta extensión ha llevado a un aumento en el rendimiento, pasando del 89.1% al 89.56% en MMLU.
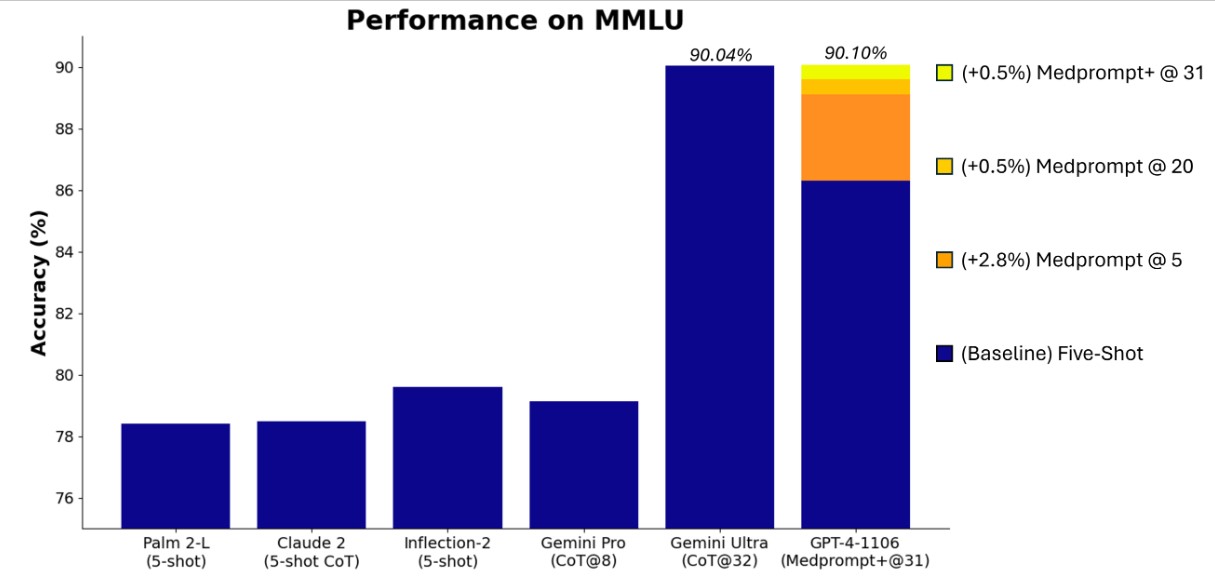
Además, Medprompt+ introduce un enfoque de cartera de dos métodos para preguntas que requieren razonamiento de múltiples pasos o respuestas factuales directas. Dependiendo de la naturaleza de la pregunta, Medprompt+ ajusta dinámicamente la contribución de la cadena de pensamiento en el proceso de respuesta. Este ajuste fino ha llevado a una mejora adicional del 0.5% en el rendimiento a través del MMLU, demostrando la eficacia de adaptar las estrategias de prompting a las necesidades específicas de cada área temática y tipo de pregunta.
Medprompt+ es un ejemplo brillante de cómo la inteligencia artificial puede ser afinada no solo para especializarse en un campo, sino para adaptarse y responder de manera efectiva a una amplia gama de desafíos intelectuales y prácticos. La capacidad de Medprompt+ para ajustar su enfoque según la pregunta planteada representa un avance significativo en la versatilidad y la eficiencia de los modelos generales de IA, abriendo nuevas posibilidades para su aplicación en una variedad de campos.
Resultados y Evaluación en MMLU
El impacto de Medprompt y su versión mejorada, Medprompt+, se evaluó extensamente en el benchmark MMLU, una herramienta de evaluación diseñada para medir la comprensión y el razonamiento de los modelos de lenguaje en una amplia variedad de temas. Los resultados obtenidos han sido notables, demostrando la eficacia de estas metodologías en la ampliación de las capacidades de un modelo generalista como GPT-4.
Con Medprompt, GPT-4 logró un impresionante 89.1% de precisión en el MMLU, un resultado significativo considerando la diversidad y complejidad de los problemas abordados. Este desempeño ya era destacado, pero con la implementación de Medprompt+, se observó un aumento adicional en la precisión, alcanzando un 89.56%. Este incremento, aunque parece modesto, es estadísticamente significativo dada la gran cantidad de problemas y la variabilidad de temas en MMLU.
Este éxito en MMLU subraya la habilidad de Medprompt+ para adaptar su estrategia de prompting a diferentes tipos de preguntas, ya sean aquellas que requieren razonamiento de múltiples pasos o respuestas más directas y factuales. Este enfoque adaptable y dinámico confirma que los modelos generales de IA, cuando se guían adecuadamente, pueden abordar eficazmente una gama mucho más amplia de desafíos intelectuales que los modelos especializados.
Conclusión y Perspectivas Futuras
La investigación y el desarrollo de Medprompt y Medprompt+ representan un hito en el campo de la inteligencia artificial. Estas metodologías no solo han mejorado la capacidad de los modelos generales de IA para especializarse en tareas específicas, sino que también han abierto nuevas vías para su aplicación en una variedad de campos. La capacidad de adaptar estrategias de prompting para abordar diferentes tipos de problemas es una innovación que promete transformar la manera en que utilizamos y entendemos la IA.
Mirando hacia el futuro, podemos anticipar que la metodología detrás de Medprompt será aplicada y adaptada a otros dominios, potencialmente llevando a avances similares en campos como la ingeniería, la educación, y más allá. El potencial para futuras investigaciones y aplicaciones prácticas es vasto, y estamos apenas comenzando a explorar las posibilidades que estos avances en IA nos ofrecen.